每日算法
新学四问
WHY【与前代优化了什么,弥补了什么空白】数据思维,程序优化
WHAT【框架,思维导图,主题框架】程序员专业词汇,日常英语
HOW【如何记忆,学习资源】多想多写多用,Leetcode
LEVEL【不是每个都学精】实际运用
PLAN
学前准备
一.基本数据结构
第一章 算法定义
在特定计算模型下,在信息处理过程中为了解决某一类问题而设计的一个指令序列。
要素:
输入:待处理的信息,即对具体问题的描述。
输出:经过处理之后得到的信息,即问题的答案。
确定性:任一算法都可以描述为由若干种基本操作组成的序列。
可行性:在相应的计算模型中,每一基本操作都可以实现,且能够在常数时间内完成。
有穷性:对于任何输入,按照算法,经过有穷次基本操作都可以得到正确的输出。
1.2性能分析预评价
三个层次:合法程序,确定尺度度量算法效率,通过对算法设计编写效率高,能处理大规模数据的程序,
时间复杂度 T(n)
度量算法执行速度并评价其效率,算法需要多少时间才能得到结果
==》针对不同规模的输入,算法的执行时间各是多少
==》统一规模算法处理时间也不相同
空间复杂度
算法所需存储空间
1.3 算法复杂度及其分析
1.3.1 O(1)⎯⎯取非极端元素
1.3.2 O(logn)⎯⎯进制转换
1.3.3 O(n)⎯⎯数组求和
1.3.4 O(n2)⎯⎯起泡排序
1.3.5 O(2r)⎯⎯幂函数
1.4 计算模型
1.4.1 可解性
1.4.2 有效可解
1.4.3 下界
1.5 递归
1.5.1 线性递归
1.5.2 递归算法的复杂度分析
1.5.3 二分递归
1.5.4 多分支递归
第二章 栈与队列
栈与队列最简单基本,但也是最重要的。JVM,CPU,Java提供对应内建类,
2.1 栈
后进先出(Last-in-first-out,LIFO),比如浏览器访问记录与回退,编辑回退。
元素:
栈容量,栈顶指针,初始化
进栈push()、出栈pop(),查栈顶peek()
Java
java.util.Stack
:push()、pop()、peek()(功能等价于top())、getSize()以及empty()(功能等价于isEmpty())
应用:数组倒置,括号匹配算法,
三种实现方式
数组
链表
LinkedList
2.2 队列
先进先出(First-In-First-Out, FIFO),羽毛球筒
2.2.1 队列ADT
Queue 接口
元素
队头、队尾、队尾加元素add(),队头删除元素poll(),查队头元素peek()
2.2.2 基于数组的实现
顺序数组,整体移动
循环数组,
性能分析,O(1)。
2.2.3 队列应用实例
循环分配器,Josephus 环
2.3 链表
数组长度必须固定,在空间效率及适应性方面还存在不足。
2.3.1 单链表
元素
首节点,末节点
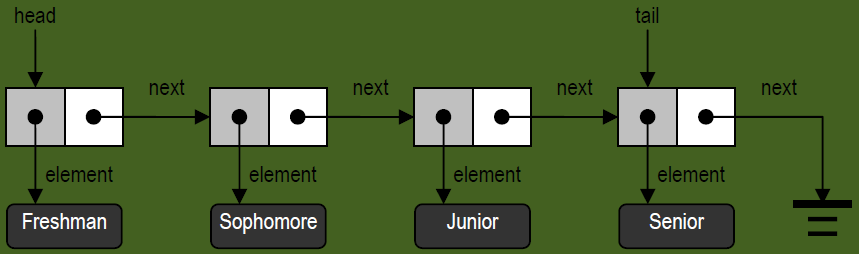
链表的第一个和最后一个节点,分别称作链表的首节点(Head)和末节点(Tail)。末节点的特征是,其next 引用为空。如此定义的链表,称作单链表(Singly linkedlist)。
与数组类似,单链表中的元素也具有一个线性次序⎯⎯若P 的next 引用指向S,则P 就是S的直接前驱,而S 是P 的直接后继。与数组不同的是,单链表的长度不再固定,而是可以根据实际需要不断变化。如此一来,包含n 个元素的单链表只需占用O(n)空间⎯⎯这要比定长数组更为灵活。
2.4 位置
2.5 双端队列
第三章 向量、列表与序列
序列(Sequence),就是依次排列的多个对象,就是一组对象之间的后继与前驱关系,是数据结构设计的基础。两种典型的序列:向量(Vector)和列表(List)。
3.1 向量与数组
3.1.1 向量ADT
第四章 树
前面所有的数据结构根据其实现方式,可以划分为基于数组实现和基于链表实现,其各有长短,数组善查找读取,修改耗时,链表反之。两者有点能结合?树或许可以回答这个问题。
术语及性质
节点的深度、树的深度与高度
树中的元素也称作节点(Node),每个节点的深度都是一个非负整数;深度为0 的节点有且仅有一个,称作树根(Root);对于深度为k (k≥1)的每个节点u,都有且仅有一个深度为k-1 的节点v 与之对应,称作u 的父亲(Parent)或父节点。定义四.2 若节点v 是节点u 的父亲,则u 称作v 的孩子(Child),并在二者之间建立一条树边(Edge)。同一节点的孩子互称“兄弟”(Sibling)。树中所有节点的最大深度,称作树的深度或高度。树中节点的数目,总是等于边数加一。
度、内部节点与外部节点
任一节点的孩子数目,称作它的“度”(Degree)。至少拥有一个孩子的节点称作“内部节点”(Internal node);没有任何孩子的节点则称作
“外部节点”(External node)或“叶子”(Leaf)。
路径
由树中k+1 节点通过树边首尾衔接而构成的序列{ (v0, v1), (v1, v2), …, (vk-1, vk) | k ≥ 0},称作树中长度为k 的一条路径(Path)。由单个节点、零条边构成的路径也是合法的,其长度为0。树中任何两个节点之间都存在唯一的一条路径。若v 是u 的父亲,则depth(v) + 1 = depth(u)。从树根通往任一节点的路径长度,恰好等于该节点的深度。
祖先、后代、子树和节点的高度
- 每个节点都是自己的“祖先”(Ancestor),也是自己的“后代”(Descendent);
- 若v 是u 的父节点的祖先,则v 也是u 的祖先;
- 若u 的父节点是v 的后代,则u 也是v 的后代。
除节点本身以外的祖先(后代),称作真祖先(后代)。任一节点v 的深度,等于其真祖先的数目。任一节点v 的祖先,在每一深度上最多只有一个。树T 中每一节点v 的所有后代也构成一棵树,称作T 的“以v 为根的子树(Subtree)”若子树v 的深度(高度)为h,则称v 的高度为h,记作height(v) = h。对于叶子节点u 的任何祖先v,必有depth(v) + height(v) ≥ depth(u)。
共同祖先及最低共同祖先
在树T 中,若节点u 和v 都是节点a 的后代,则称节点a 为节点u 和v 的共同祖先(Commonancestor)。每一对节点至少存在一个共同祖先。在一对节点u 和v 的所有共同祖先中,深度最大者称为它们的最低共同祖先(Lowerestcommon ancestor),记作lca(u, v)。每一对节点的最低共同祖先必存在且唯一。
有序树、m 叉树
在树T 中,若在每个节点的所有孩子之间都可以定义某一线性次序,则称T 为一棵“有序树(Ordered tree)”每个内部节点均为m 度的有序树,称作m 叉树。
二叉树
每个节点均不超过2 度的有序树,称作二叉树(Binary tree)。不含1 度节点的二叉树,称作真二叉树(Proper binary tree),否则称作非真二叉树
(Improper binary tree)。在二叉树中,深度为k 的节点不超过2k 个。高度为h 的二叉树最多包含2h+1-1 个节点。由n 个节点构成的二叉树,高度至少为⎣log2n⎦。在二叉树中,叶子总是比2 度节点多一个。
满二叉树与完全二叉树
若二叉树T 中所有叶子的深度完全相同,则称之为满二叉树(Full binary tree)高度为h 的二叉树是满的,当且仅当它拥有2h 匹叶子、2h+1-1 个节点。若在一棵满二叉树中,从最右侧起将相邻的若干匹叶子节点摘除掉,则得到的二叉树称作完全二叉树(Complete binary tree)。由n 个节点构成的完全二叉树,高度h = ⎣log2n⎦。在由固定数目的节点所组成的所有二叉树中,完全二叉树的高度最低。
第五章 优先队列
第六章 映射与词典
第七章 查找树
第八章 串
第九章 图
第十章 算法思想
二、常用算法
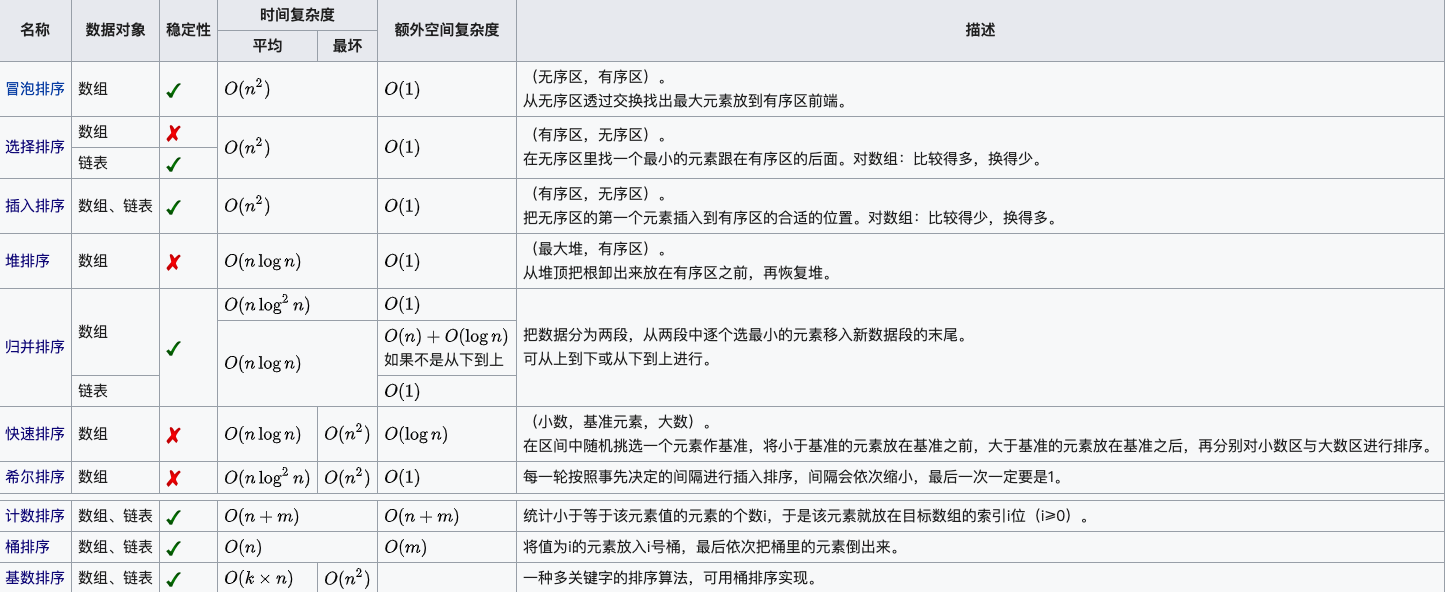
排序


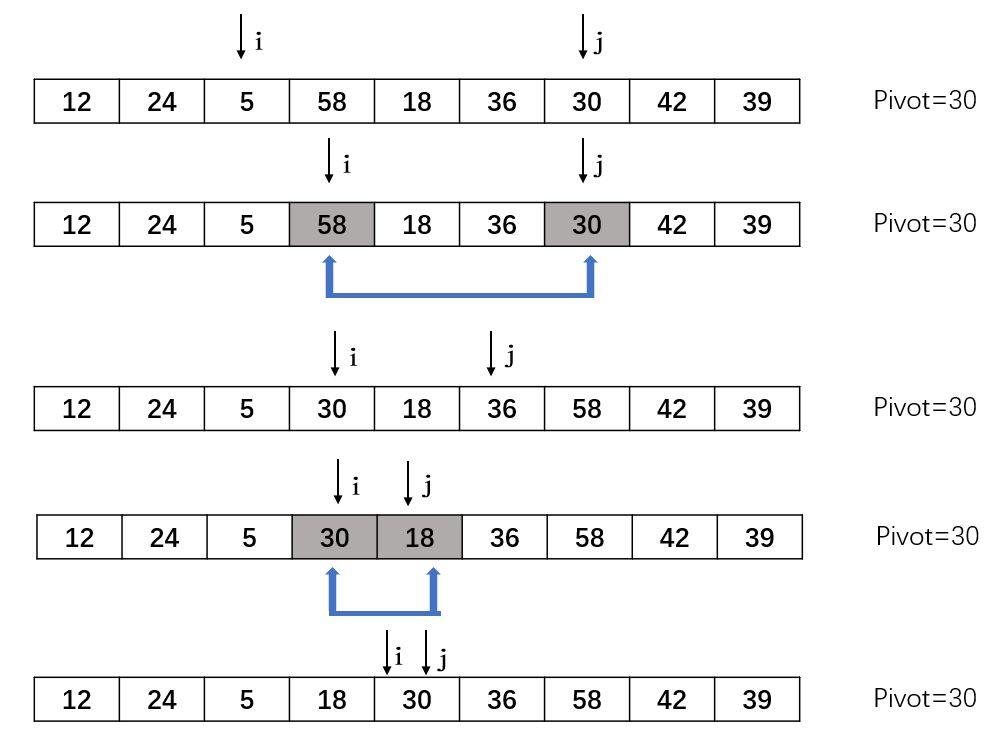
查找
三、算法题
2.18题目:序号-题目
思路1:
思路1
优点:
缺点:代码1:
代码1思路2:
思路2
优点:
缺点:代码2:
代码2参考文献:数据结构预算法(Java描述)邓俊辉